
Building a Scalable MLOps Foundation in the Cloud – Part 1: Small Teams Setup
A practical guide to building a lightweight MLOps foundation for small teams (1–3 people) without overengineering.
Intro
Machine learning (ML) is no longer a niche capability – it’s becoming a core part of modern business strategies. But taking ML models from development to production is a huge leap, especially without solid MLOps practices in place.
For small teams – typically 1 to 3 data scientists – it’s essential to start with a lightweight, scalable setup that enables rapid experimentation while maintaining version control, automation, and reproducibility.
In this first part of the series, we’ll explore how small ML teams can set up an effective MLOps workflow in the cloud using a minimal, yet powerful, architecture.
1. The Problem with Manual ML Workflows
If you’ve experienced the chaos of manually copying Jupyter notebooks between laptops or trying to remember exactly which library version you used last week, you already know the pain. Without proper version control, consistent environments, or automated processes, your small team can lose days (or even weeks) just backtracking on previous experiments. Model drift can sneak by undetected, because there’s no structured monitoring. And if a business stakeholder asks, “Why did our model accuracy drop last month?” you might be stuck sifting through old notebooks and ad-hoc notes, hoping to find a clue.
2. The MLOps Goals for Small Teams
The main goal here is to keep your daily ML operations from collapsing under their own weight. Collaboration should be easy, and every step—from data ingestion to model deployment—should be trackable. Automation is also key. When you’ve only got a handful of data scientists, you can’t afford to waste time manually retraining or re-deploying models. Add to this the ability to detect model performance issues early and you have a good baseline for a smooth, scalable workflow.
In short, you want to improve collaboration, enforce version control (for both code and data), automate training and deployments where possible, and make sure you’re keeping a close eye on how your models are actually performing in the wild.
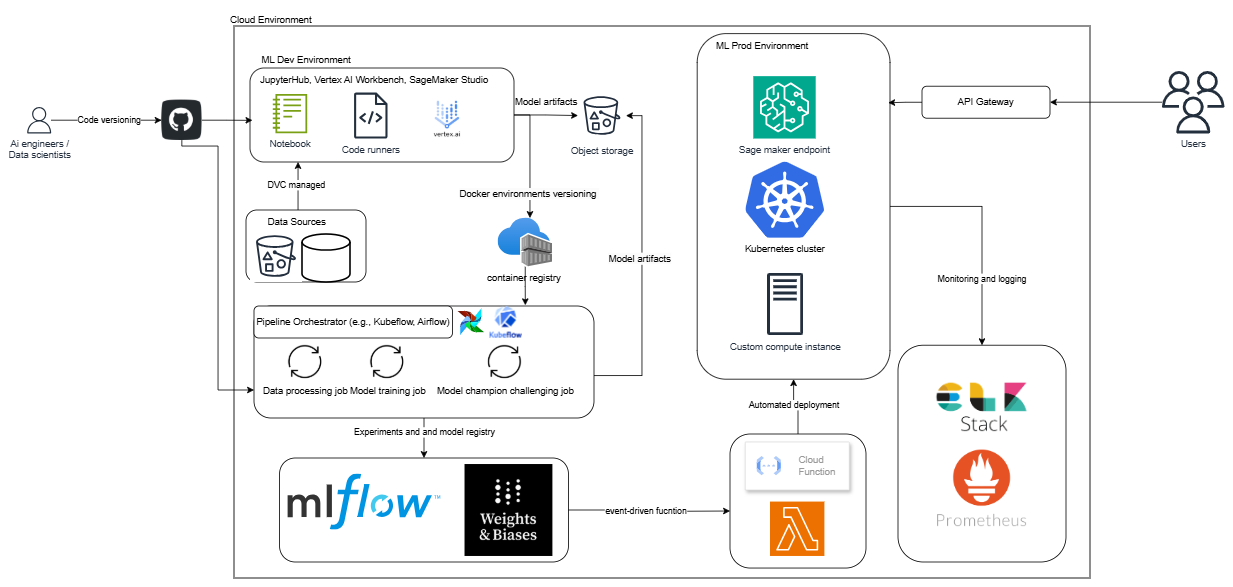
3. Architecture Overview
Let’s talk about what the end-to-end pipeline might look like, using simple but powerful tools. I like to imagine this as a straightforward workflow that any new team member could step into without feeling overwhelmed. Here’s how you can piece it together:
-
Cloud ML Development Environment
You could use something like JupyterHub or SageMaker Studio, which allows everyone to develop and experiment in the same place. This fosters collaboration and reduces the classic “It works on my machine!” problem. -
Git-Based Version Control
Hosting your repositories on GitHub (or a similar platform) makes it easy to collaborate, open pull requests, and trigger automated CI/CD pipelines whenever you push new code. It’s also your source of truth for how your code has evolved over time. -
Data Version Control (DVC)
This is a lifesaver when dealing with ever-evolving datasets. It integrates neatly with Git so that your dataset versions live side by side with your code revisions. -
Cloud Object Storage
Storing large datasets and model artifacts in something like Amazon S3 keeps your repositories from ballooning. It also means everyone can reliably access the data they need. -
Container Registry
Whether it’s Docker Hub or GitHub Container Registry, you’ll want to store images for both training and inference. This way, each environment is versioned and can be reproduced if you ever need to roll back or debug. -
Pipeline Orchestrator
Tools like Kubeflow Pipelines or Airflow help you automate steps like data processing, model training, and evaluation. Instead of manually running scripts in the right order, let the orchestrator handle it. -
Model Registry & Experiment Tracking
MLflow or Weights & Biases can manage your models, track hyperparameters and metrics, and record which model version is the best performer. -
Event-Driven Deployment Functions
A service like AWS Lambda can watch for new “approved” model versions in your registry and automatically deploy them. This removes the tedious waiting around for someone to manually flip a switch. -
ML Production Environment
You’ll need a place to serve your models, such as SageMaker Endpoints, a Kubernetes cluster, or some custom infrastructure. The key is choosing an environment that can autoscale as demand grows. -
Monitoring & Logging Stack
Collecting logs and metrics with something like Prometheus or an ELK Stack helps you see, in real time, if your model’s performance is drifting. This means fewer surprises and faster reactions to issues. -
API Gateway
Finally, hooking up an API Gateway allows external clients or internal services to request predictions securely and reliably from your model endpoint.
4. Deployment Strategy
In a small team environment, you can’t afford to have complicated, manual processes for deploying models. Instead, go for an event-driven approach. Whenever a model is newly registered and marked as “good to go,” an event triggers an automated workflow—maybe it spins up a container, updates an endpoint, or runs a canary test. If everything checks out, the new model gets fully deployed, and traffic shifts accordingly.
Canary deployments (where a small percentage of traffic tests the new model before it’s fully rolled out) can be incredibly helpful to ensure that no unexpected regressions slip through. Meanwhile, auto-scaling endpoints take care of unpredictable workloads, so you’re not scrambling to handle sudden spikes in requests.
Finally, don’t overlook monitoring. You should have dashboards and alerts set up to warn you if accuracy starts dipping. Early detection of model drift is what keeps your team focused on solving problems rather than digging through logs.
5. Benefits of This Setup
One of the biggest advantages of this architecture is that it’s lightweight. You’re not trying to replicate the complexity of a massive enterprise system. Instead, you’re focusing on what your small team really needs: easy collaboration, automated training and deployments, and reliable monitoring. Because you’re using cloud-native services and open-source tools, it’s pretty flexible—you can migrate or extend the stack as your projects grow or your budget changes.
This approach also encourages good MLOps habits from the start. When a data scientist joins the team, there’s already a clear place to store code, track experiments, and push new models. There’s no confusion or guesswork about who changed which file or how to replicate an old run.
6. What’s Next?
Laying this foundation means you can develop, deploy, and monitor your ML models with minimal friction. But as your team scales from three data scientists to ten, or you start tackling more complex problems, you’ll need to consider more sophisticated orchestration, resource management, and governance policies. That’s where Part 2 comes in—we’ll delve into how this small-team approach evolves to handle bigger challenges and bigger teams.
Until then, feel free to reach out with any thoughts, questions, or war stories of your own MLOps journey. There’s nothing better than learning from real-world successes (and failures).
👉 Stay tuned for Part 2: Scaling MLOps for Medium Teams – it’s on its way!