
Building a Scalable MLOps Foundation in the Cloud – Part 2: Medium Teams Setup
How to upgrade your MLOps stack and workflows as your team grows beyond notebooks and quick hacks.
Intro
In Part 1, we looked at how small ML teams (usually 1 to 3 people) can set up a lightweight and practical MLOps foundation in the cloud. But as your team grows and more models make it to production, things start to get messy—fast.
When you hit 4 to 10 people, you’re no longer a tiny team. You’ve got more experiments running, more models to maintain, and more opinions in every discussion. That simple setup that once worked great? It starts showing cracks.
This Blog is about scaling that original setup without losing your mind. We’ll go over the new challenges medium teams face, and how to upgrade your MLOps stack just enough to stay fast, collaborative, and in control.
1. The Growing Pains of Medium-Sized ML Teams
When you’re a team of 2 or 3, it’s easy to sync up. You might even remember which model lives where just from memory (guilty 🙋). But once your team grows, you start noticing things like:
- Experiments being duplicated because no one knew someone else already tried it
- Pipeline steps failing because someone renamed a column
- Models going to production without proper checks
- Metrics being collected in five different ways, none of them consistent
This is where you need more structure—but without making everything feel like a giant enterprise bureaucracy.
2. What Changes (and What Doesn’t)
The good news? You don’t have to throw out everything from Part 1. Most of it still applies.
But you do need to level things up. Here’s how:
-
Shared ML environments:
Move from single-user JupyterHub or SageMaker Studio setups to shared environments with clear user permissions. -
Better version control:
Go beyond basic Git and DVC. Enforce clear branching strategies, structured pull requests, and consistent versioning practices. -
Automated pipelines:
Replace manual pipeline triggers with fully automated CI/CD workflows integrated into your pipeline orchestrator (like Kubeflow or Airflow). -
Advanced model registry:
Extend basic model tracking by adding structured approval workflows and tagging (MLflow or Weights & Biases). -
Reusable codebase:
Transition from single notebooks to a more structured, modular codebase with reusable components. -
Separate environments:
Move away from a single deployment environment to clearly defined development, staging, and production environments.
MLOps Architecture (Medium Team Setup)
As your team grows, so does the need for clarity and structure in your MLOps architecture. Below is an example of how a medium-sized team (4–10 people) can organize their MLOps stack in the cloud:
- Shared ML development environment using tools like JupyterHub, SageMaker Studio, or Vertex AI Workbench
- Version control for both code (via Git) and data (via DVC)
- Pipeline orchestrators like Kubeflow or Airflow to automate data processing, training, and evaluation
- Container registry to version and store Docker environments for training and inference
- Model registry and experiment tracking using MLflow or Weights & Biases
- Event-driven deployments triggered via serverless functions (e.g., AWS Lambda or Google Cloud Functions)
- CI/CD pipelines powered by tools like Jenkins for automated builds, testing, and integration.
- Automated deployments managed by ArgoCD, providing GitOps-based workflows for deploying models reliably and quickly.
- Staging and production environments for model serving using SageMaker Endpoints, Kubernetes clusters, or custom infrastructure
- Inference data storage in a cloud bucket (e.g., Amazon S3) to capture model predictions, which can later be reused for feature engineering, model retraining, or drift analysis
- Monitoring and observability stack (Prometheus, ELK) to track metrics, logs, and model drift
- API Gateways to securely serve predictions to internal teams or users
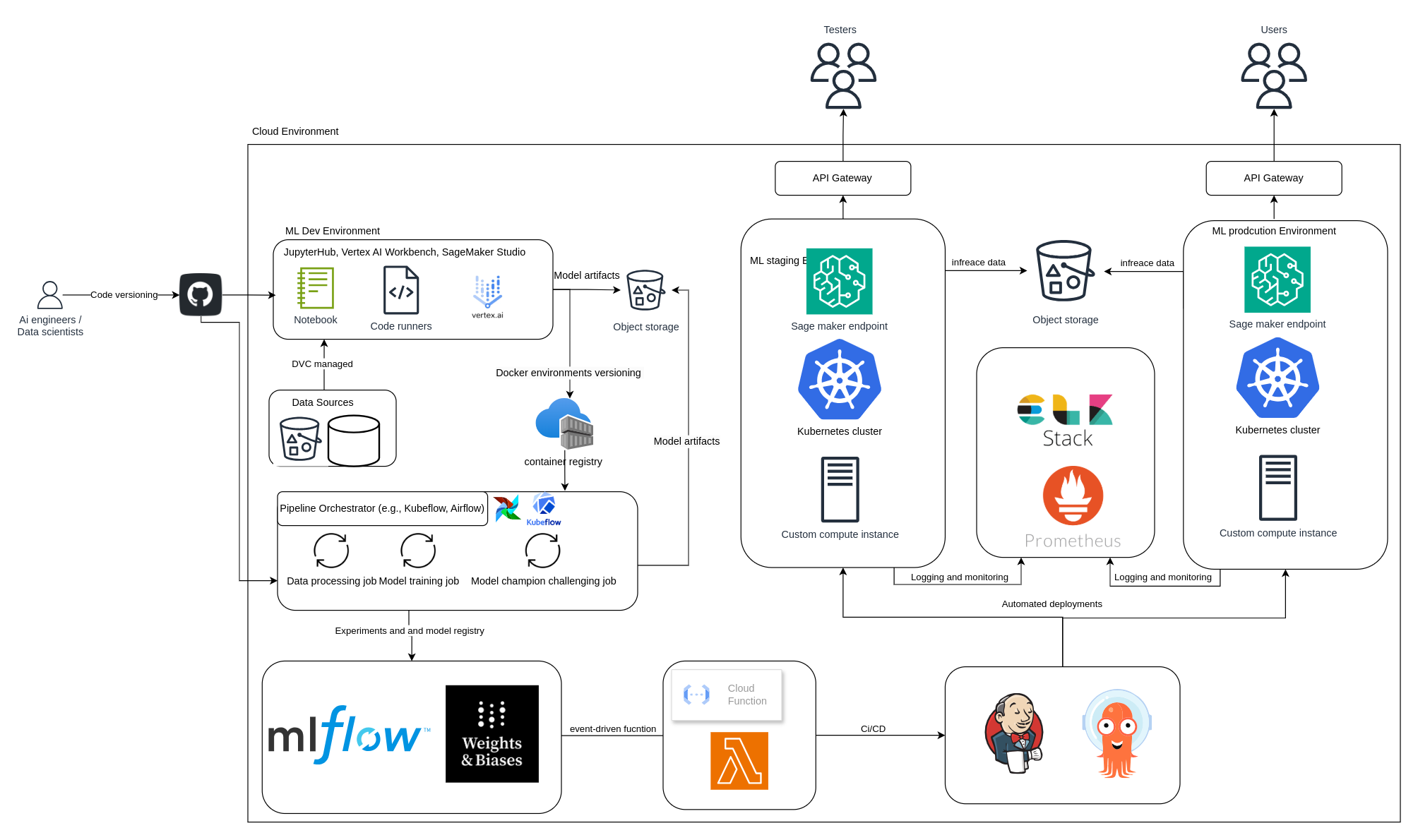
This architecture gives your team the balance it needs: speed when you want to move fast, and structure when things get complex. You don’t need to go full-enterprise to scale—just be intentional with your tools, workflows, and responsibilities.
5. Monitoring, Retraining & Feedback Loops
With more models in production, you’ll want:
- Dashboards for model metrics, latency, and drift
- Alerts when performance drops below a threshold
- Scheduled or triggered retraining when the data changes
- User feedback loops if you have human-in-the-loop applications
You’re not just “deploying and forgetting” anymore—now it’s about maintaining models over time.
6. Security, Roles & Access
More teammates = more access. It’s time to be thoughtful about security.
- Set up role-based access to notebooks, pipelines, and models
- Use secret managers (Vault, AWS Secrets Manager) to store API keys and credentials
- Keep audit logs so you know who changed what, and when
Even small incidents (like overwriting a model accidentally) can be costly when you’re growing fast.
Final Thoughts
Growing a team is exciting—but it also means your MLOps setup has to grow with you.
The key is to build on top of your existing foundation. Keep what works, automate what’s slowing you down, and put just enough structure in place to stay productive without overcomplicating things.
In Part 3, we’ll explore how this setup evolves for large enterprise teams—with a focus on compliance, multi-region infrastructure, resource optimization, and cross-team collaboration at scale.