
Building a Scalable MLOps Foundation in the Cloud – Part 3: Large Teams Setup
What happens when you go beyond 10 team members, multiple projects, and high compliance requirements? Here’s how large teams scale MLOps.
Intro
In Part 1 and Part 2, we looked at how small and medium teams can build effective MLOps stacks in the cloud. But when you hit enterprise scale with more people, more models, and more regulations the complexity grows fast.
Here’s how to manage that complexity without slowing down.
1. Think “Platforms” not “Projects”
At this level, ML projects shouldn’t reinvent the wheel. Instead, build ML platforms with centralized services that everyone can use:
- Model Registries: MLflow, SageMaker Model Registry for tracking and promoting models.
- Feature Stores: Feast, Vertex AI ensure feature consistency and reusability.
- Experiment Tracking: Shared MLflow or Weights & Biases servers to keep all training metadata in one place.
This avoids duplicated work and makes cross-team collaboration smoother.
2. Advanced Automation and CI/CD Pipelines
With more teams and more models, you need pipelines you can trust:
- Separate training pipelines from deployment pipelines.
- Use multi-stage environments clearly defined stages (Development → QA → Staging → Production) with structured approvals.
- Add model validation steps: fairness, drift, and performance checks.
- Adopt GitOps with tools like ArgoCD for safer, auditable infrastructure changes.
No more manual deploys. Every action is automated and version-controlled.
3. Dynamic and Cost-Efficient Scaling
Avoid burning cloud budget by managing compute smartly:
- Use Kubernetes Horizontal Pod Autoscaler for inference workloads.
- Train with spot instances or on-demand autoscaling compute.
- Configure endpoints to scale-to-zero when idle and burst on demand.
Elastic scaling is key for big workloads and big savings.
4. Enterprise-Grade Governance and Access Control
At scale, governance isn’t a bonus it’s mandatory:
- Apply RBAC to data, models, and pipelines.
- Enforce audit logging on all training and deployment actions.
- Integrate compliance checks (GDPR, HIPAA, ISO 27001) into your pipelines.
Security and compliance should be built into your workflow, not bolted on later.
5. Monitoring Everything (Seriously)
You need to know what’s happening everywhere:
- Track model accuracy, latency, and drift.
- Monitor training pipelines and infrastructure health.
- Centralize logs and metrics with Prometheus, Grafana, or ELK.
No visibility = no control. Monitoring at scale is non-negotiable.
6. Splitting Infrastructure for Scale and Security
As your organization grows, splitting your infrastructure into multiple dedicated cloud accounts greatly improves security and scalability. Here’s a recommended structure:
-
Development Account:
Dedicated to data scientists for experimentation and training. Includes JupyterHub, SageMaker Studio, Vertex AI, Kubeflow/Airflow pipelines, and experiment tracking (MLflow). -
CI/CD Account:
Automates your CI/CD processes with tools like Jenkins, ArgoCD, and Lambda. This account handles deployments across all environments. -
Staging Account:
Pre-production environment where models are tested thoroughly. Includes Kubernetes, SageMaker endpoints, and API gateways for controlled testing. -
Monitoring & Logging Account:
Collects and manages logs, metrics, and monitoring alerts using Prometheus and ELK Stack, ensuring observability across all other accounts. -
Production Account:
Production environment for live models. Features Kubernetes clusters and SageMaker endpoints with automated scaling and zero manual access—deployments handled entirely via CI/CD.
From Medium to Large: Structuring by Account
In a medium setup, a single cloud account often suffices. At enterprise scale, this quickly becomes a bottleneck. To handle larger complexities securely and efficiently, here’s how splitting your infrastructure looks in practice:
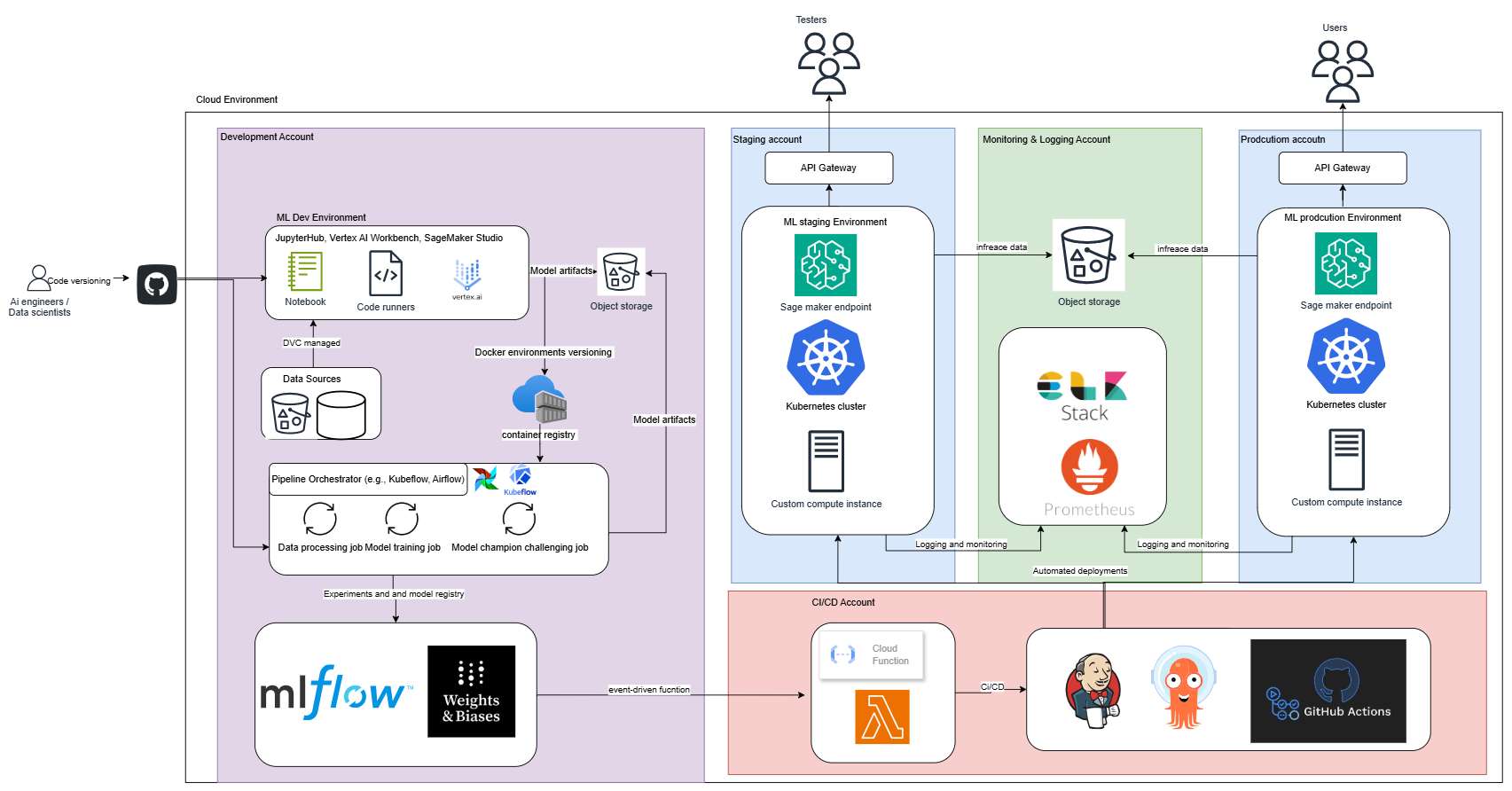
- Development Account for training, experimentation, and versioning.
- CI/CD Account dedicated to automated builds, deployments, and infrastructure management.
- Staging Account for thorough testing and validation before production.
- Monitoring & Logging Account to centrally observe system health and performance.
- Production Account for stable, secure, and highly available model serving.
This separation provides clarity, reduces risks, and enhances security and compliance.
Final Thoughts
MLOps isn’t just a technical challenge, it’s how you build trust in machine learning at scale.
Whether you’re one person training a model in a notebook, or a large team deploying hundreds of models into production, the fundamentals stay the same:
Automation, security, visibility, and collaboration.
Start simple, scale carefully, and never lose focus on what matters delivering real value with machine learning.
This series was just the beginning. The rest is up to you.
If you found this series helpful, feel free to share it or reach out for feedback!